Web scraping w Pythonie nie jest taki trudny. To nic innego jak proces wyodrębniania danych ze stron internetowych. Jeżeli chodzi o cele takiego procesu to w zależności od potrzeb mogą to być dane z różnych źródeł, np.:
- Branża nieruchomości – oferty domów lub mieszkań
- Marketing i sprzedaż
- Porównywanie cen produktów
- Monitoring cen biletów lotniczych
Wyzwania dla webscrapingu na dużą skalę
Masz scrapować 100-150 stron internetowych dziennie. Z jakimi wyzwaniami musisz się zmierzyć?
- Dynamiczna treść oparta o JavaScript. Strony, które są oparte o JavaScript i AJAX są trudne do scrapowania. Jedną z metod ogarnięcia tego tematu jest wykorzystanie PhantomJS.
- Jakość danych. Jeżeli po pobraniu danych chcesz je od razu przetwarzać, np. z użyciem algorytmów ML lub AI musisz zwrócić uwagę na jakość danych. Puste rekordy, niepotrzebne spacje lub znaki specjalne nie są mile widziane w naszej bazie.
- Captcha. Wszyscy wiemy o co chodzi, zapobiegać robotom, które spamują na całego. Pobieranie danych z miejsca, które wykorzystuje captcha jest trudne, ale nie niemożliwe. Z wykorzystaniem oprogramowania pośredniczącego, które przechwyci captche możesz kontynuować podróż robota po konkretnej witrynie.
- Ciągły rozwój Twojej aplikacji. Raczej mało prawdopodobne, że raz napisany kod będzie służyć Tobie na długo. Z czasem zwiększysz skalę, ilość stron internetowych, które będą scrapować. To powoduje również wchodzenie w dodatkowe technologie, jak np. kontenery.
- Zmiana zawartości witryny (np. zmiana nazwy div’a). Co jakiś czas widzimy odświeżanie witryn. Zmiana UI, często całkowita zmiana szablonu. Powoduje to pewne komplikacje w naszym skrypcie, ponieważ musimy poświęcić dodatkowy czas na zweryfikowanie nowej struktury strony.
Protip: Jeżeli nie chcesz dowiedzieć się przypadkiem, że dana strona zmieniła UI, postaraj się stworzyć test w aplikacji do CI, która wychwyci takie zmiany. - Przechowywanie danych. Raczej nie chcesz trzymać danych w plikach .txt albo .csv. Pomyśl o jakieś bazie dla Twojej aplikacji, np. skorzystaj z Free Tier na AWS.
- Technologie zapobiegające scrapowaniu. Temat, który przewija się przy dużych witrynach. Częste odpytywanie serwera możesz doprowadzić do zablokowania Twojego adresu IP. W tej sytuacji możesz zastosować usługę proxy, która będzie wykorzystywać kilka adresów IP. Scrapy umożliwia wdrożenie takiego rozwiązania. Pamiętaj również o kwestiach etycznych – możesz dodatkowo przeczytać o tym we wpisie Webscraping – jak zacząć?
Biblioteki w Pythonie
Dlaczego Python? To wynika z jego popularności w tym obszarze, stąd w poniższym zestawieniu jak i innych przykładach, które będę wspominać oparte są o kod Pythona. Są różne podejścia do web scrapingu, poniżej poznasz kilka bibliotek, które możesz wykorzystać.
Request HTTP
Requests HTTP – Jeżeli chcesz scrapować konkretną podstronę najpierw musi pobrać jej zawartość HTML. Najlepiej zrobić to zapisując odpowiedź z żądania do obiektu. Sama biblioteka jest łatwa w użyciu. Krótki wstęp poniżej, a dokumentację znajdziesz w linku powyżej.
#Przyklad uzycia biblioteki requests
import requests
r = requests.get("https://www.wp.pl") #Wyciagnij zawartość witryny w HTML
BeautifulSoup
BeautifulSoup – Mamy już pobrane dane z konkretnej witryny, ale teraz czeka nas następny etap, wyciągnięcia tego co najbardziej nas interesuje. BeautifulSoup jest bardzo pożyteczną biblioteką Pythona, która służy do wyodrębnienia danych ze strony internetowej. Bazując na tym co mamy, biblioteką requests używamy do pobrania danych ze strony HTML, a następnie BeautifulSoup wykorzystujemy do parsowania strony. W poniższym przykładzie możesz zobaczyć jak wygląda wykorzystanie dwóch bibliotek.
from bs4 import BeautifulSoupimport requests
r = requests.get("https://stooq.pl") #Pobranie zawartości
soup = BeautifulSoup(r.text, "html.parser") #Parsowanie strony
print(soup.find_all('a')) #Wyswietlenie wszystkich elementów bedacych linkami
Scrapy
Scrapy – Następne cudeńko do scrapingu. Z tym, że w tym przypadku mamy do czynienia z frameworkiem, który pozwala na więcej. Poprzednia biblioteka BeatifulSoup pozwala na parsowanie strony, a w tej sytuacji możemy napisać kompleksowe narzędzie, które jako robot internetowy przeszuka strony internetowe, wydobędzie to co nas interesuje. Zachęcam do przerobienia tutorialu na https://docs.scrapy.org/en/latest/intro/tutorial.html, który przeprowadzi Ciebie przez kilka kroków, od tworzenia pierwszego bota, po uzupełnianie o dodatkowe argumenty.
Przykład skryptu
W ramach przykładu zapoznasz się z budową podstawowego skryptu, który:
- Korzysta z bibliotek BeautifulSoup, urllib.request oraz csv
- Pobiera dane z serwisu Stooq.pl – tabela wycen akcji z WIG20.
- Zapisuje pobrane dane do pliku .csv
Na warsztat weźmiemy tabelę ze spółkami z WIG20 w serwisie Stooq.pl
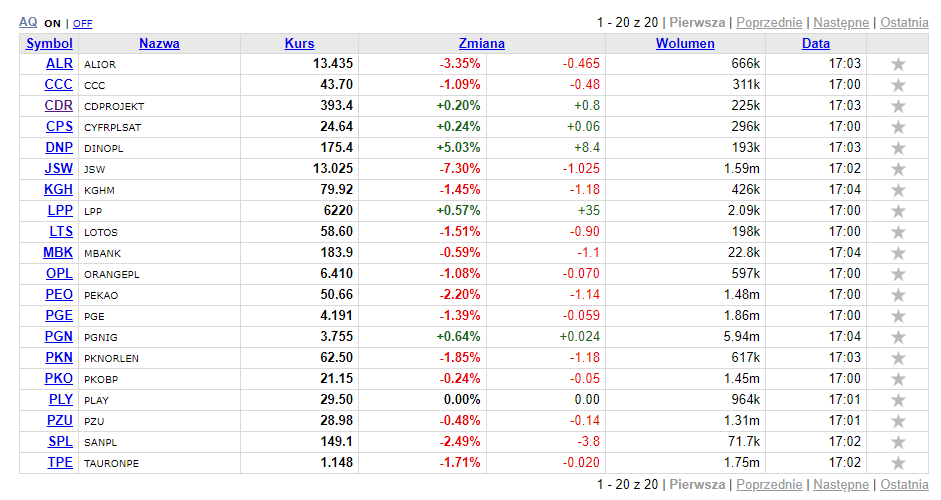
Żeby wiedzieć jak się do tego zabrać musimy najpierw zbadać jak wygląda struktury strony. W celu sprawdzenia kliknij prawym przyciskiem myszy i wybierz opcję Zbadaj element/Zbadaj.
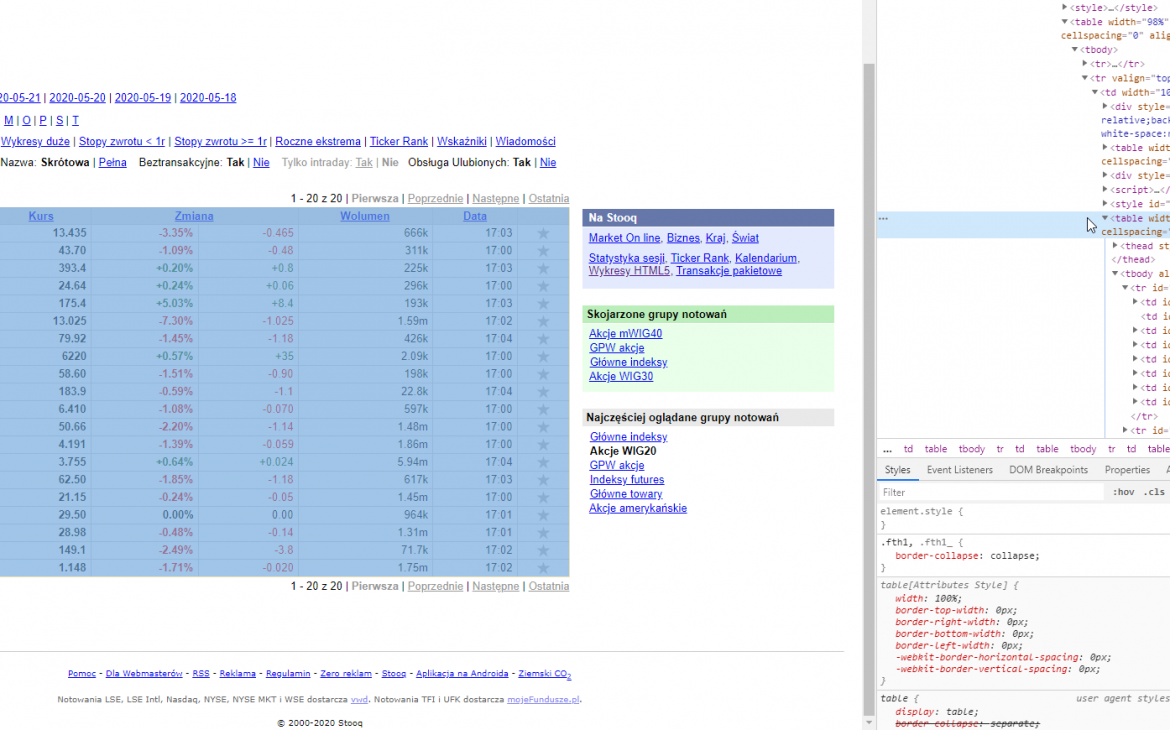
W tabeli przechowywane są dane, które posłużą nam do przechwycenia i obróbki. Każdy z elementów, który nas interesuje to wiersz w tabeli <tr>.
Przejdźmy zatem do samego kodu. Pierwszym krokiem jest import bibliotek, których użyjemy do naszego web scrapera. Wykorzystamy BeautifulSoup do parsowania html, urllib do połączenia się ze stroną oraz biblioteką csv, która pozwoli na zapisanie danych wyjściowych do pliku w takim formacie.
from bs4 import BeautifulSoup import urllib.request import csv
Następnym krokiem jest zdefiniowanie adresu URL, który posłuży nam jako źródło danych.
# zrodlo danych stronawww = 'https://stooq.pl/t/?i=532'
No dobra, mamy dwa podstawowe elementy – import bibliotek oraz wskazanie źródła danych. Mam nadzieje, że administratorzy Stooq.pl nie mają mi za złe 🙂
Na tym etapie sprawdź czy w Twoim środowisku programistycznym masz wszystkie wymagane biblioteki i uruchom testowo kod. Oczywiście ten fragment nie wyświetli nam żadnych szczegółów. Najważniejsze, aby wykonał się bez błędów.
Jeżeli masz już to za sobą, możemy zająć się parsowaniem html’a z wykorzystaniem BeautifulSoup, obiekt będzie przechowywany w zmiennej „soup„.
# zapytanie do strony internetowej i zwrocenie wyniku w postaci kodu html oraz przypisanie do zmiennej "obiekt"
obiekt = urllib.request.urlopen(stronawww)
# parsowanie html z uzyciem BeautifulSoup i przypisanie do zmiennej "soup"
soup = BeautifulSoup(obiekt, 'html.parser')
Dla testów uruchom skrypt i zobacz czy wykona się bez błędów. Jeżeli wszystko jest ok, możesz dodać do kodu i uruchomić ponownie.
print(soup)
W efekcie skrypt powinien zwrócić kod HTML, następnie przystępujemy do przeszukiwania wskazanej tabeli. W naszym przypadku to tabela o nazwie „fth1” (kliknij prawym przyciskiem myszy na tabelę i opcja Zbadaj element/Zbadaj).
# sprawdzanie czy istnieja dane w tabeli
tabela = soup.find('table', attrs={'class': 'fth1'})
ilosc_wierszy = table.find_all('tr')
# zliczenie liczby wierszy w tabeli, ale pominiecie pierwszego jako naglowka, wynikiem powinno byc 20
print('Liczba spółek', len(ilosc_wierszy)-1)
Rezultatem powinna być wartość – Liczba spółek: 20
Ok, co dalej…
Skupimy się na stworzeniu listy oraz uzupełnieniu jej o nazwy kolumn w nagłówku.
# stworzenie listy oraz dopisanie do niej naglowka dla naszej tabeli
wiersze = []
wiersze.append(['Symbol', 'Nazwa', 'Kurs', 'Zmiana', 'Zmiana', 'Wolumen', 'Data'])
print(wiersze)
Powyższy fragment utworzy listę oraz wyświetli pierwszy wiersz.
Teraz mamy już bazę i możemy w pętli przeszukać całą tabelę, żeby wyciągnąć potrzebne nam dane. Do tego posłuży nam fragment poniżej. Zwróć uwagę na komentarze dodane do kodu. W tej sytuacji nie bierzemy pod uwagę nagłówka, ponieważ on nie zawiera przydatnych danych.
# petla przeszukująca cala tabele
for wiersz in ilosc_wierszy:
data = wiersz.find_all('td')
# sprawdz czy kolumny posiadaja dane
if len(data) == 0:
continue
# pisz zawartosc kolumny do zmiennej
symbol = data[0].getText()
nazwa = data[1].getText()
kurs = data[2].getText()
zmiana1 = data[3].getText()
zmiana2 = data[4].getText()
wolumen = data[5].getText()
data = data[6].getText()
# dolacz wynik do wiersza
wiersze.append([symbol, nazwa, kurs, zmiana1, zmiana2, wolumen, data])
print(wiersze)
Na szczęście w tym miejscu nie ma potrzeby wykonywania dalszego procesu czyszczenia danych. Mam na myśli usuwania niechcianych znaków lub innych niespodzianek, które utrudniają ich czytelność.
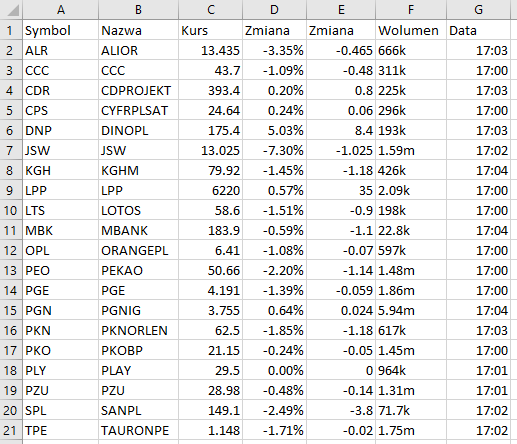
W ostatniej części naszego skryptu chcemy zapisać wynik naszej pracy do pliku .csv
# Tworzy plik csv i zapisuje wiersze do pliku wyjsciowego
with open('wig20.csv','w', newline='') as plik_wynikowy:
csv_output = csv.writer(plik_wynikowy)
csv_output.writerows(wiersze)
Tak wygląda gotowy plik .csv
Powodzenia w przygotowaniu swojego web scrapera 😉